Few weeks ago we (TouK) revealed on Github our latest open source project - Nussknacker. What is it and why should you care?
Why?
First, some history: more than year ago one of our clients decided it’s high time for Real Time Marketing. They had pretty large data streams and lots of ideas for marketing campaigns, so one of the key success factors was the ability to process the data fast. We prepared a POC based on Apache Flink and it turned out that it’s really great piece of technology - fast and accurate.
There was just one problem - how to write and customize processes? Flink, as many modern stream processing engines, provides rich and friendly DSL, both in Java and Scala. But for our client that was not really enough. See, they are enterprise that do not employ developers - they have many decent, competent analysts who know the business and SQL - but not Java or (Heaven forbid…) Scala.
Nussknacker to the rescue!
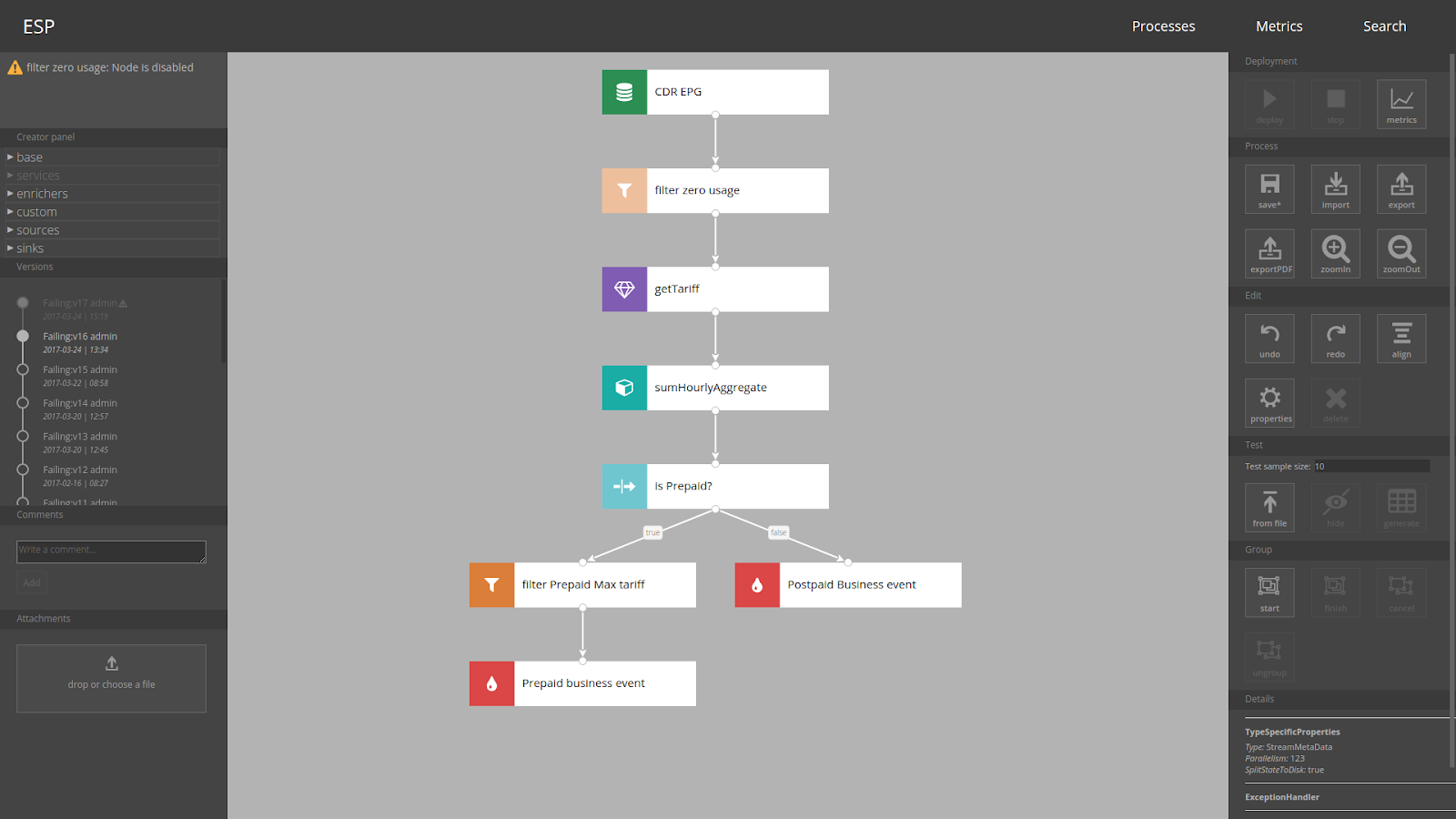
You draw a diagram, fill the details (like filter expressions - “
#input.usageData > 0” or SMS/mail content), then you press the Deploy button and voilà - your brand new process in running on Flink cluster!
Of course first somebody (that is, developer) has to prepare data sources (most probably Kafka topics), design data model (POJOs or case classes) and implement actions - like sending email or sending some event to another Kafka topic. But once model of data and external services are defined, an analyst can define and deploy processes all by him/herself.
More features
Sounds a bit scary to let your users run stream processes with GUI? Bad filter condition can have serious performance implications if you’re dealing with streams of tens of thousands of events per second... That’s why we let user test their diagrams first - each test case can be generated by sample of real data coming from e.g. Kafka and then run in Flink sandbox mini-cluster.
We have also many more features that make working with Nussknacker and Flink easier: subprocesses, versioning, generating PDF documentation, migration between environments and last but certainly not least - integration with InfluxDB/Grafana to provide detailed insight into how process is doing:
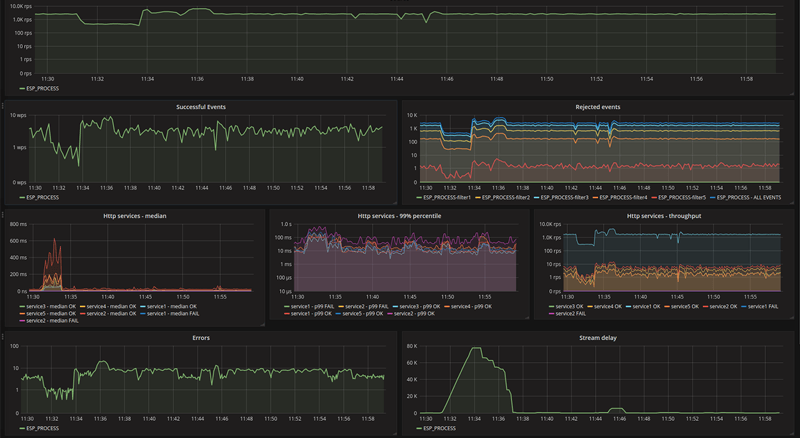
Where can I use it?
What are Nussknacker use cases? Our main deployments deal with RTM (Real Time Marketing). One of our clients started with RTM and then found out that Nussknacker is also great choice for fraud detection in real time. Industries we are working with include telcos, banks and media companies. We are also thinking about other possibilities - for example IoT.
Sounds cool?
If you are interested in easy access for semi-technical analysts to streaming data - give Nussknacker a try!
You can find the code at Github: https://github.com/touk/nussknacker, we also have a nice, Docker-based quickstart: https://touk.github.io/nussknacker/Quickstart.html.
And if you are coming to Flink Forward next week in Berlin - join me on Wednesday afternoon to hear more - https://berlin.flink-forward.org/kb_sessions/touk-nussknacker-creating-flink-jobs-with-gui/.
In next days/weeks we’ll post more information on TouK blog both on Nussknacker architecture and internals and on interesting use cases - stay tuned :)



